Data Science Engineering
Optimizing Text Chunking for RAG-Enhanced LLM Applications
Enhance LLM and RAG workflows with DOM-aware text chunking. Learn how leveraging HTML's structure preserves context, reduces redundancy, and optimizes semantic text segmentation for improved AI performance.

Introduction
Text chunking—dividing large text into smaller, manageable pieces—is essential in natural language processing. Traditional methods often split text arbitrarily, leading to chunks that lack context or are improperly sized. This issue is exacerbated in HTML documents, where ignoring the inherent structure can disrupt the semantic flow of content.
To address this, we developed a DOM-aware text chunking approach that leverages the hierarchical structure of HTML documents. By splitting text according to DOM element boundaries and incorporating contextual paths, we create semantically meaningful chunks that enhance downstream processing tasks.
Understanding HTML's Hierarchical Structure
HTML and XML are markup languages that structure data hierarchically, represented by the Document Object Model (DOM). In the DOM:
Elements: Nodes in the tree representing parts of the document.
Attributes and Text: Contained within these nodes.
Hierarchy: Defined by parent-child relationships.
This structure provides semantic meaning. For example, a <p> tag located directly after an <h1> (heading) tag is likely to be a paragraph about the topic contained in the heading’s text. Preserving this hierarchy during chunking helps maintain the content's semantic integrity.
Our Dynamic DOM-Aware Chunking Approach
We treat each text-containing element as a node and split text based on the DOM element boundaries (e.g., <p>, <div>, <section>). This ensures chunks align with more meaningful content divisions. To add context, we include the path of section headers leading to each content piece, prefixing chunks with the hierarchy of headings (e.g., <h1>, <h2>, <h3>). This preserves some of the longer-range semantic relationships that might be lost in naive splitting.
Formulating the Optimization Problem
We model the chunking process as an optimization problem to systematically determine the optimal (examined) solution for splitting text while satisfying constraints like maximum chunk size and full coverage of text elements.
Variables and Definitions
E = {1, 2, , n}: Set of all text elements.
S = {1, 2, , m}: Set of possible chunks (splits).
Wj: Size (cost) of (possible) chunk j.
M: Maximum allowable chunk size.
Yj in {0, 1}: Indicator variable for inclusion of chunk j.
Objective Function
We aim to minimize the total cost (size) of the included chunks:
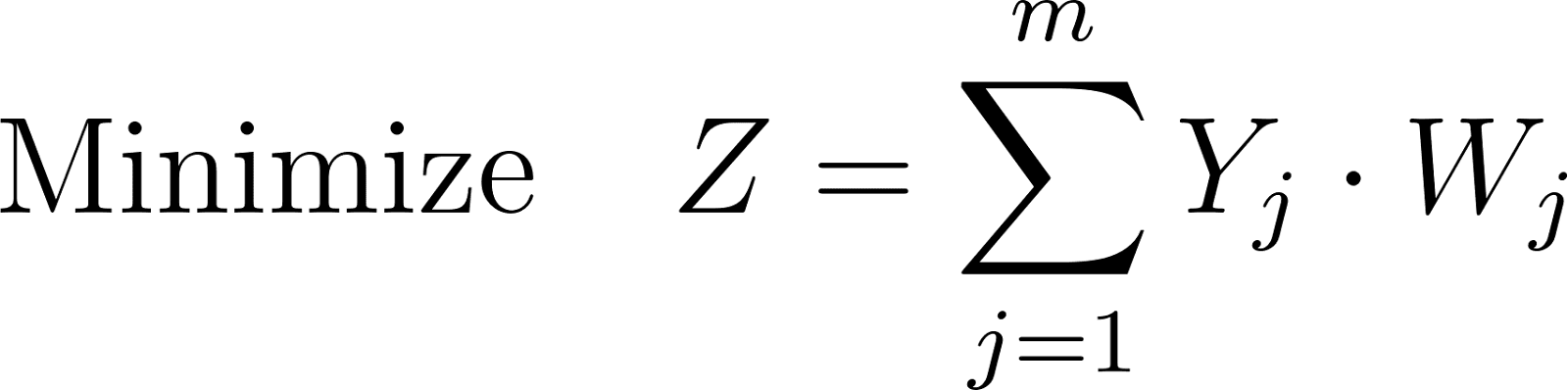
This objective inherently minimizes redundancy due to overlapping elements, as overlapping elements in different chunks contribute to the total cost multiple times. The following three constraints are applied to effectively solve the optimization problem:
1. Inclusion Constraint: All text elements must be included in at least one chunk:
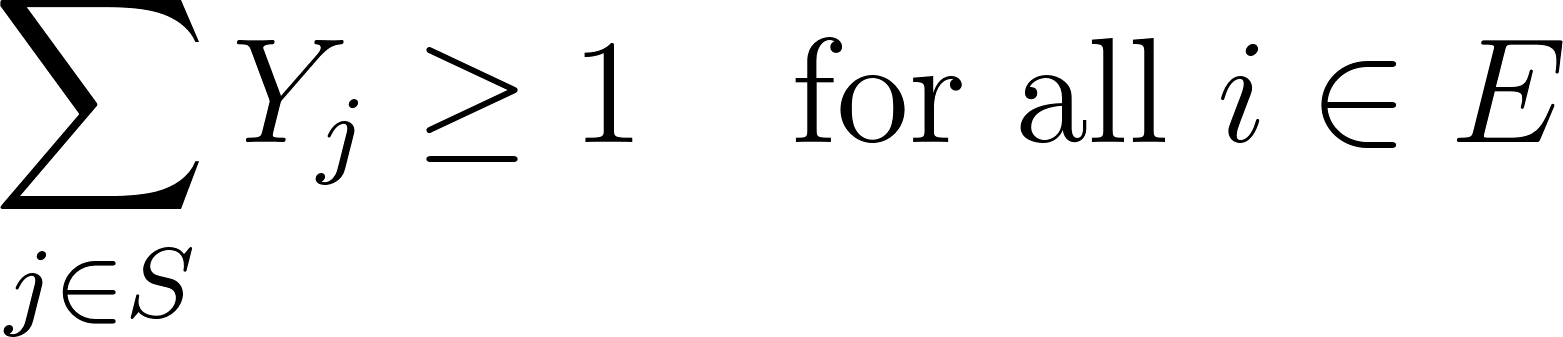
This ensures that every text element i is covered by at least one included chunk.
2. Chunk Size Constraint: Each included chunk must not exceed the maximum size M

This ensures included chunks do not exceed maximum size M.
3. Variable Domains:
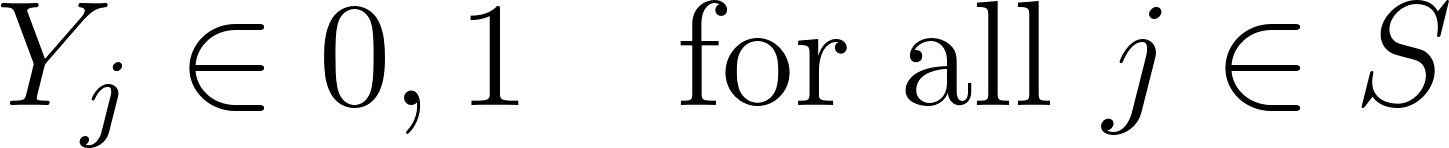
Practical Considerations
Limiting the Number of Chunks
Due to computational constraints, we limit the number of chunks by:
Preprocessing: Generate a manageable subset of feasible chunks based on heuristics.
Chunk Generation: Use strategies like breadth-first search or heuristic approaches to identify candidate chunks.
Auto Backoff for Maximum Chunk Size
A critical pre-step in our optimization is selecting an appropriate maximum chunk size, denoted as M. If M is set too small, some chunks may exceed this limit, rendering them unfeasible for inclusion in the solution. To ensure all chunks can be accommodated, we implement an auto backoff mechanism. This approach dynamically adjusts M—increasing it incrementally until a feasible solution is found where all chunks adhere to the size constraint. This ensures that no text elements are left unprocessed due to overly restrictive chunk size limits.
Handling Overlaps
Overlapping elements increase total cost. By minimizing Z , the model favors solutions with fewer, larger chunks up to size M, reducing redundancy.
Solvability Condition
The optimization problem is solvable if the maximum chunk size M is at least equal to the minimum cost required to include any text element. Specifically, M must be at least as large as the size of the largest root-to-leaf path in the DOM tree. If M is smaller than this minimum cost for any element, no feasible solution exists that includes all text elements without violating the chunk size constraint. Therefore, to ensure all text elements can be included, we must adjust M to be at least the maximum of these minimum costs.
Benefits of the Dynamic DOM-Aware Approach
Semantic Preservation: Aligning chunks with DOM elements maintains content integrity.
Enhanced Context: Including hierarchical paths enriches chunks with contextual information.
Reduced Redundancy: Minimizing the number of chunks lowers duplication, improving efficiency.
Conclusion
Our dynamic DOM-aware chunking method leverages HTML's hierarchical structure to create semantically meaningful chunks. By formulating this process as an optimization problem, we balance chunk size and context, which enhances tasks like information retrieval and natural language understanding. This approach improves both the processing and comprehension of web-based text data, advancing the development of context-aware text processing systems.